-
 ほぷしぃ TOPページ
<<
特集PC技術
ほぷしぃ TOPページ
<<
特集PC技術
Java言語入門 〜C言語を学んだ君へ〜
[1] final
finalキーワードについての説明をします。
これを使うことで、バグの少ないソースを書くことができます。
また、「定数」の作り方についても説明します。
「final」とは文字通り「最後」という意味で、これ以上変更したくない場合に使用します。
finalの書式
final class A { // classの前にfinalを付ける
:
}
final void method() { // 戻り値の前にfinalを付ける
:
}
final int VALUE = 10; //型宣言の前にfinalを付ける
先頭にfinalをつけます。finalにつけたものに関して変更が禁止されます。
finalは、クラス、メソッド、メンバ変数それぞれで使うことができます。
クラスのfinalを付けた場合には継承ができません。
メソッドにfinalを付けた場合には、オーバーライドによる書き換えができません
変数のにfinaつけた場合には、C言語の[定数]のような役割を果たします。
#define VALUE 10
これとほぼ同じです。
しかし、Javaの定数は「型」を持ち、「修飾子」を付けられます。
つまり、C言語の定数より機能が上です。
定数名は「大文字で書くことが一般的」であり、これについてはC言語と共通しています。
補足として、上記の書き方でも十分定数の役割を果たしますが、基本的にそのような書き方をしません。
定数は次のように書きます。
static final int VALUE = 10; // 基本的な定数の宣言方法
サンプルプログラム
public class Java09_02 {
public static void main(String args[]) {
FinalClass2 fc2 = new FinalClass2();
//fc2.a = 20; final変数は値の変更ができない
fc2.func();
}
}
class FinalClass{
//final定数を宣言
final public int a = 10;
//finalメソッドを定義
final public void func(){
System.out.println("funcメソッド");
}
}
class FinalClass2 extends FinalClass{
//final public void func(){} finalメソッドはオーバーライドできない
}
実行結果

finalを使ったプログラムを書いてみました。
コメント部分の//を消してみればわかると思いますが、変更ができません。
このようにこれ以上変更する予定がない場合などに用いられます。
[2] 継承とアクセス修飾子
継承関係におけるアクセス修飾子の効果について説明します。
「パッケージ」を学習していない段階では、アクセス修飾子をすべて理解できません。
ここでは、アクセス修飾子について少しだけ説明します。
「パッケージ」については、第11回パッケージを見てください。
アクセス修飾子の復習
第8回で説明したように、アクセス制御には以下の方法がありました。
| アクセス修飾子 | 制御の強さ | 機能 |
|---|---|---|
| public | 弱い | 全てのクラスからアクセスを許可 |
| protected | 少し弱い | 同じパッケージ、継承先からのアクセスを許可 |
| private | 強い | 同じのクラスからのアクセスを許可 |
| なし | 少し強い | 同じパッケージからのアクセスを許可 |
次の項目で、継承とこれら4種類のアクセス制御について説明します。
アクセス修飾子の効果
継承の場合のアクセス修飾子の効果を、メンバ変数を例に説明します。
次のソースを見てください。
アクセス修飾子のプログラム
class Super {
public int a;
protected int b;
private int c;
int d;
public super() {
a = b = c = d = 10;
}
}
class Sub extends Super {
public Sub() {
super();
System.out.println("a="+a);
System.out.println("b="+b);
//System.out.println("c="+c); ここだけコンパイルエラー
System.out.println("d="+d);
}
}
public class Java09_03{
public static void main(String args[]){
Sub sub = new Sub();
}
}
実行結果
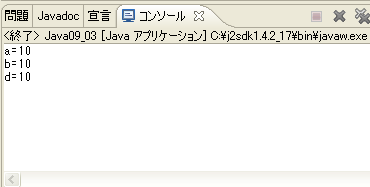
スーパークラスSuperに4種類のアクセス制御を持たせたint型を定義しています。
サブクラスSubで各int型のメンバ変数にアクセスを試みます。
結果、「private」のみアクセスができません。
アクセス制御方法の一覧と比較して、理解ができたと思います。
この例では、「public」はすべてのクラスからアクセスできるので良いとしても、
「protected」と「アクセス修飾子なし」の違いがわかりにくいです。
その違いは、第11回「パッケージ」で説明します。
今は、「protected」は継承した先からアクセスできると覚えておいてください。
[3] オブジェクトのキャスト
オブジェクトのキャストについて説明します。
基本データ型のキャストとの違いを学んでください。
基本データ型の違い
キャストするには基本データ型のキャストは次のように行いました。
double value1 = 1.414;
int value2 = (int)value1; // int型にキャスト
double value3 = value2; // キャストしてdouble型に戻す
大きいデータ型から小さいデータ型にキャストする場合は「(データ型)」を使っています。
次にオブジェクトをキャストする方法を説明します。
B b1 = new B();
A a = b1; // A型にキャスト
B b2 = (B)a; // キャストしてB型に戻す
AとBはオブジェクトです。
B型のオブジェクトをA型にキャストし、それをB型に戻しています。
ここで注意することは、AはBのスーパークラスです。
この継承関係が成り立つ時のみ、キャストが行えます。
例えば、次のクラス関係があったとします。
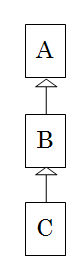
この場合、
・BはAにキャストできる
・CはBにキャストできる
・CはAにキャストできる
以上の3パターンのみキャストできます。
キャストした場合のオブジェクトと基本データ型の違いを説明します。
まず、基本データのキャストについてです。次のソースを見てください。
キャストのサンプルプログラム
public class Java09_04 {
public static void main(String args[]) {
double value1 = 1.414;
int value2 = (int)value1;
System.out.println(value2); // int型にしたデータを出力
System.out.println((double)value2); //double型に戻して出力
}
}
実行結果
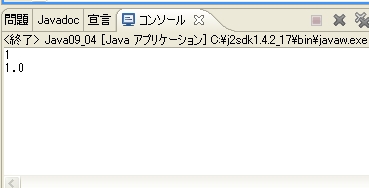
一度キャストしたデータを元の型に戻しても、失ったデータは戻りません。
当然といえば当然です。次にオブジェクトのキャストです。
次のソースを見てください。
オブジェクトのサンプルプログラム
class A {
int a;
public A() {
a = 10;
}
}
class B extends A {
int b;
public B() {
super();
b = 20;
}
}
public class Java09_05 {
public static void main(String args[]) {
B b = new B();
A a = b;
System.out.println(a.a);
//System.out.println(a.b); クラスBの変数は使えない
B b1 = (B)a;
System.out.println(b1.b); // クラスBの変数が使える
}
}
実行結果
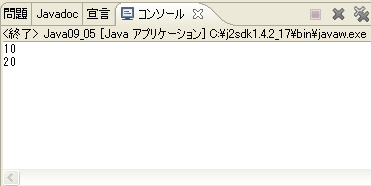
ソース中、コメントアウトした処理があります。
それは「System.out.println(a.b);」で、当然エラーになる処理です。
理由は、クラスAにキャストしたために、クラスBの機能が使えなくなったからです。
ない機能を使えるはずがありません。しかし、一度クラスAにキャストしたオブジェクトを、
元のクラスBにキャストすると、クラスBの機能が使えるようになります。
オブジェクトのキャストでは、基本データ型のキャストと異なり、機能(データ)がなくなりません。
キャストをしても、メモリ上にはクラスBの情報が残ります。
オーバーライドとキャスト
キャストをしてもデータは消えないと説明しました。
しかし、キャストしたクラスにない機能は使用できませんでした。
では、キャスト先とキャスト元の両方にある機能を見てみましょう。
つまり、「オーバーライドしたメソッド」はどのような結果になるでしょう。
次のソースを見てください。
オーバーライドしたメソッド
class C {
public void print() {
System.out.println("クラスCです");
}
}
class D extends C {
public void print() {
System.out.println("クラスDです");
}
}
public class Java09_06 {
public static void main(String args[]) {
D d1 = new D();
C c = d1;
c.print(); // キャストしたあとメソッドの呼び出し
D d2 = (D)c;
d2.print(); // 元の型にキャストしてメソッドの呼び出し
}
}
実行結果
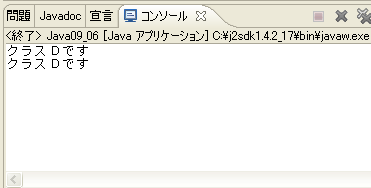
Dクラスのオブジェクトを、Cクラスにキャストした時とDクラスに戻した時
それぞれで、メソッドを呼び出しています。
クラスCです
クラスDです
と表示されるように思えますが、それは誤りです。
実際はキャストしていても、元のクラスのメソッドが呼び出されます。
少しわかりにくいですが、この点に注意してください。
しかし、これを利用すると、「ポリモーフィズム」を実現する大きな利点になります。
それについては、次のページで説明します。